从最底层原理出发,六张动图讲清楚 KV 缓存如何让 LLM 推理提速 5 倍——以及为什么第一个 Token 总是最慢。
你肯定注意到过:每次用 ChatGPT 或 Claude,第一个 Token 总是要等一会儿才出来,然后剩下的内容几乎瞬间流式涌现。
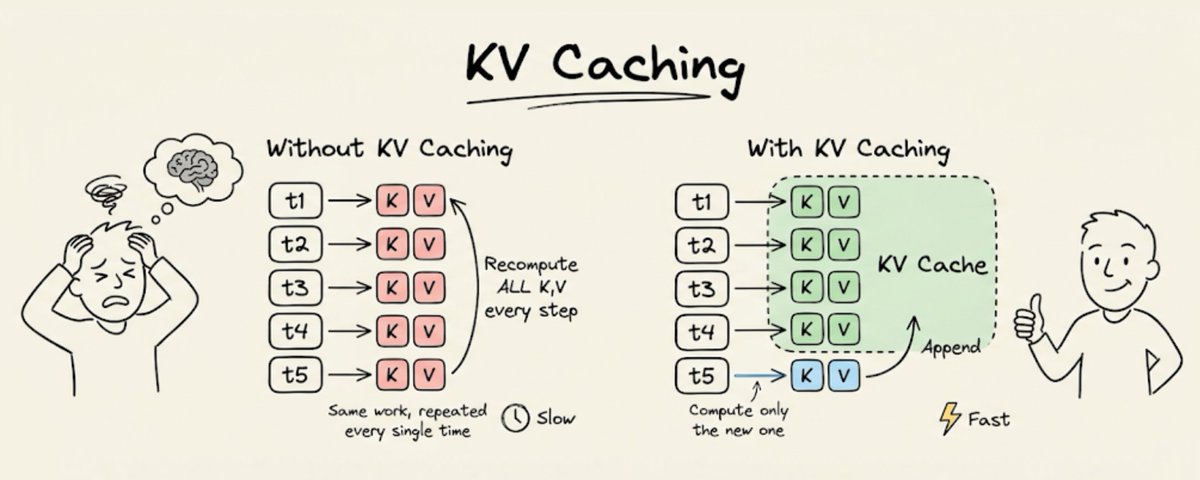
这背后是一个刻意为之的工程决策,叫 KV 缓存(Key-Value Cache),目的就是让大语言模型推理更快。
在进入技术细节之前,先看一个有 KV 缓存和没有 KV 缓存的对比:

现在我们从最底层原理出发,一步步搞懂它。
第一部分:大语言模型如何生成 Token
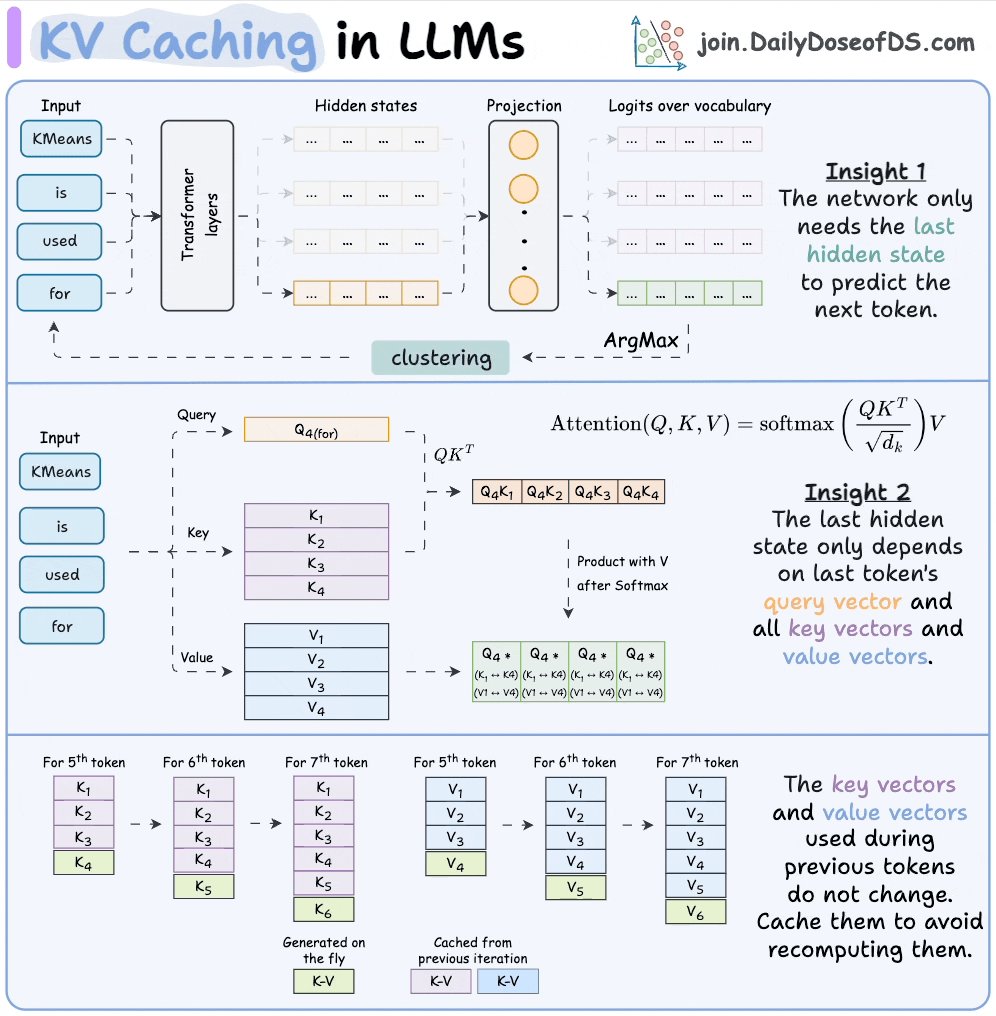
Transformer 处理所有输入 Token,每个 Token 都会得到一个隐藏状态(Hidden State)。这些隐藏状态被投影到词汇表空间,产生 Logits——词汇表中每个词的得分。
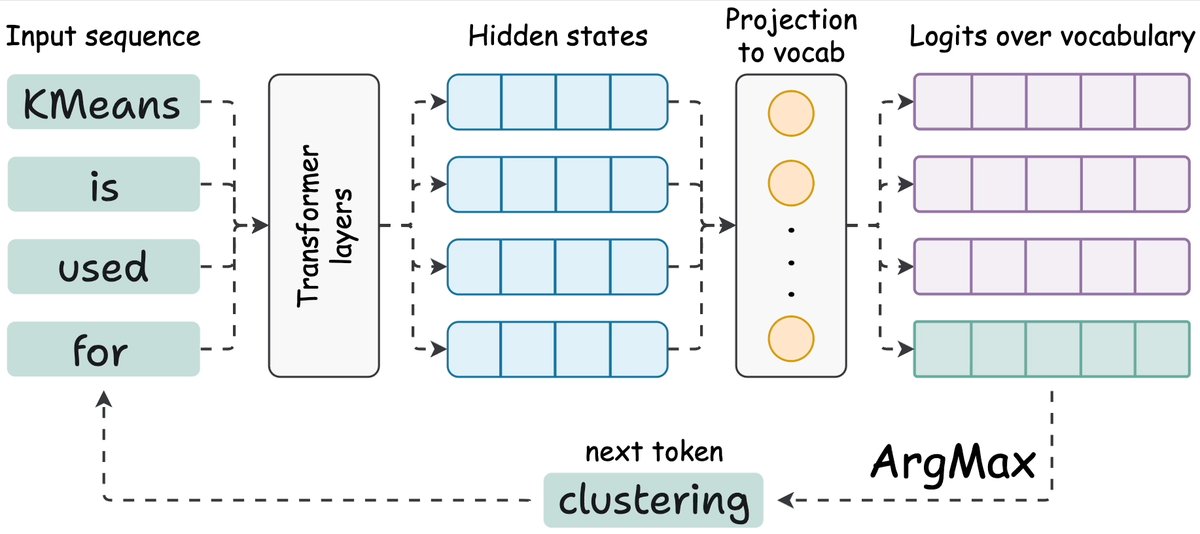
但真正有用的,其实只有最后一个 Token 的 Logits。你从中采样,得到下一个 Token,把它追加到输入末尾,然后重复这个过程。
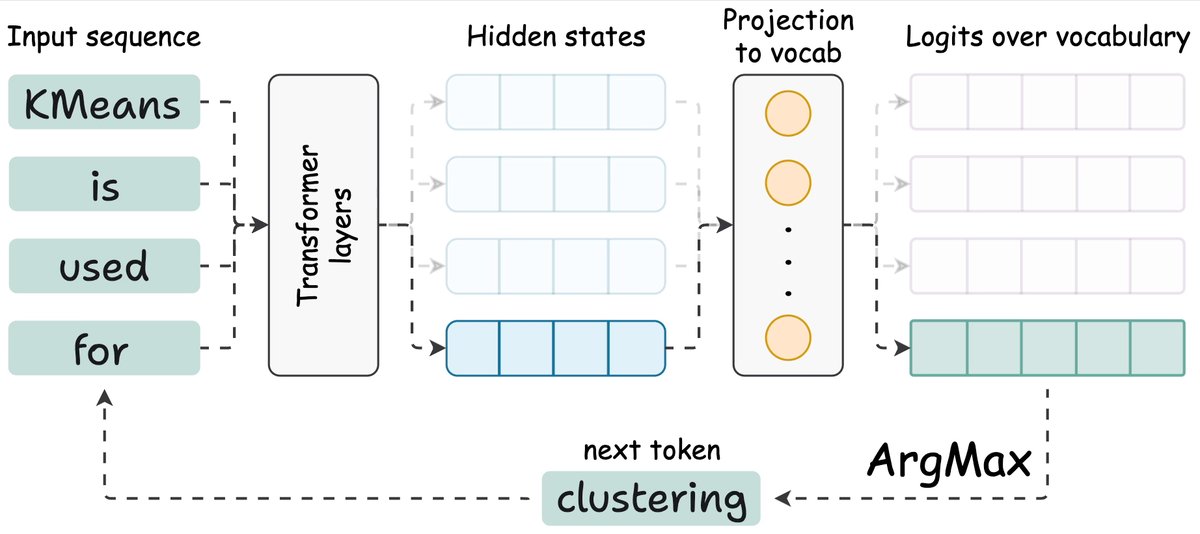
这就是关键洞察:要生成下一个 Token,你只需要最新一个 Token 的隐藏状态。其他所有隐藏状态都是中间产物。
第二部分:注意力机制到底在算什么
在每个 Transformer 层内部,每个 Token 都会得到三个向量:查询向量(Query, Q)、键向量(Key, K)和值向量(Value, V)。注意力机制用 Q 和 K 相乘得到分数,再用这些分数对 V 加权求和。
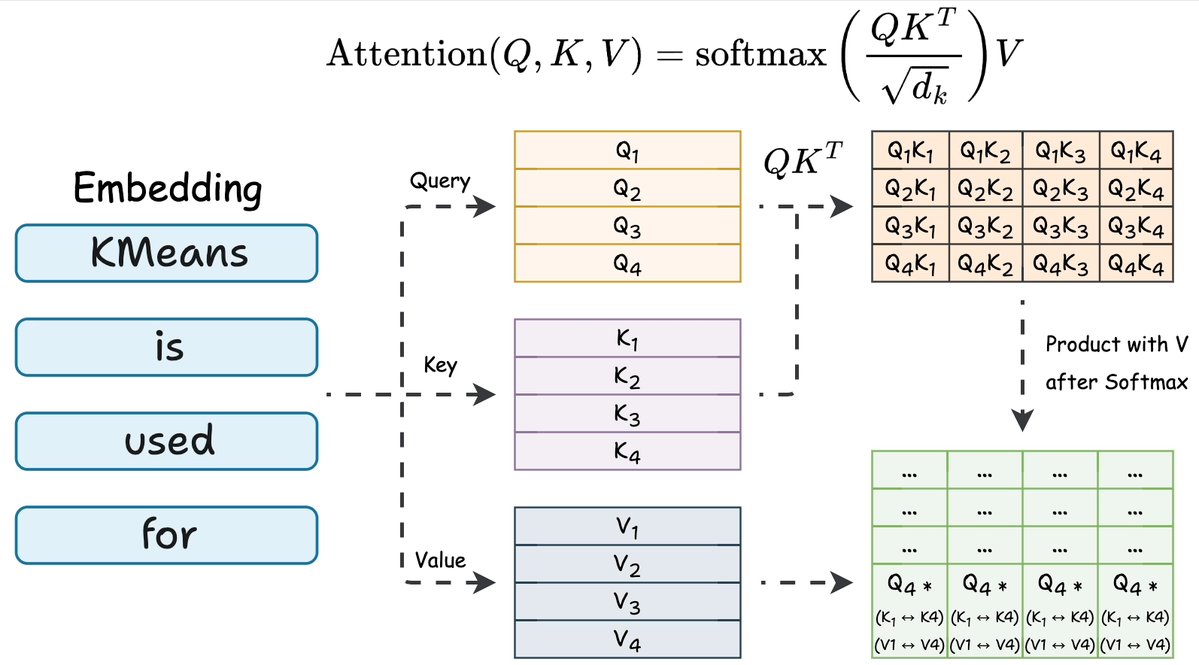
现在只看最后一个 Token。
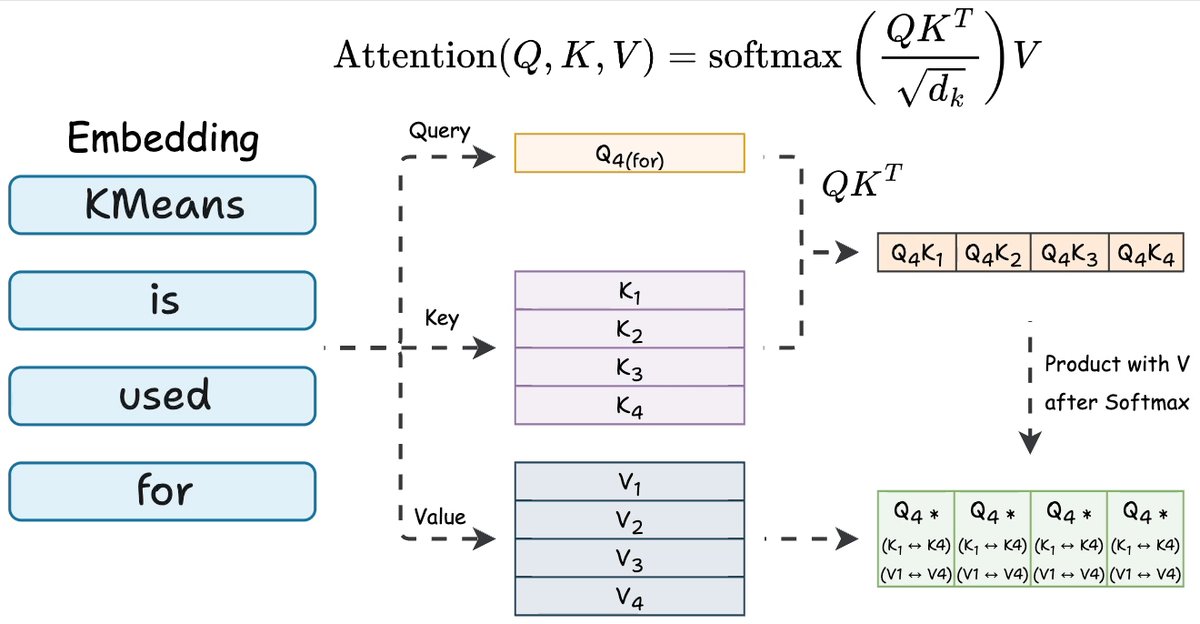
QK^T 矩阵的最后一行用到的信息是:
- 最后一个 Token 的查询向量
- 序列中所有 Token 的键向量
这一行最终的注意力输出用到的信息是:
- 同一个查询向量
- 所有 Token 的键向量和值向量
所以,要算出我们唯一需要的那个隐藏状态,每个注意力层都需要最新 Token 的 Q,以及所有 Token 的 K 和 V。
第三部分:冗余在哪
生成第 50 个 Token 需要 Token 1 到 50 的 K 和 V 向量。生成第 51 个 Token 需要 Token 1 到 51 的 K 和 V 向量。
Token 1 到 49 的 K 和 V 向量早就计算过了,而且没有任何变化——同样的输入,同样的输出。但模型每一步都在从头重新计算它们。
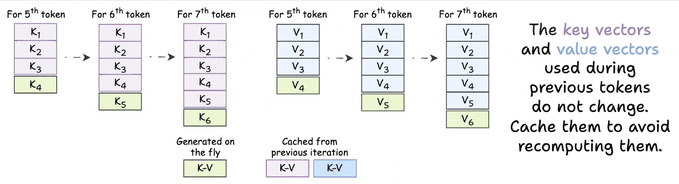
每一步做 O(n) 的冗余计算。整段生成累积下来,就是 O(n²) 的算力浪费。
第四部分:怎么修
与其每一步重新计算所有 K 和 V 向量,不如把它们存起来。每个新 Token 来的时候:
1. 只计算最新 Token 的 Q、K 和 V 2. 把新的 K 和 V 追加到缓存里 3. 从缓存取出之前所有的 K 和 V 向量 4. 用新 Q 和缓存中的全部 K、V 运行注意力计算
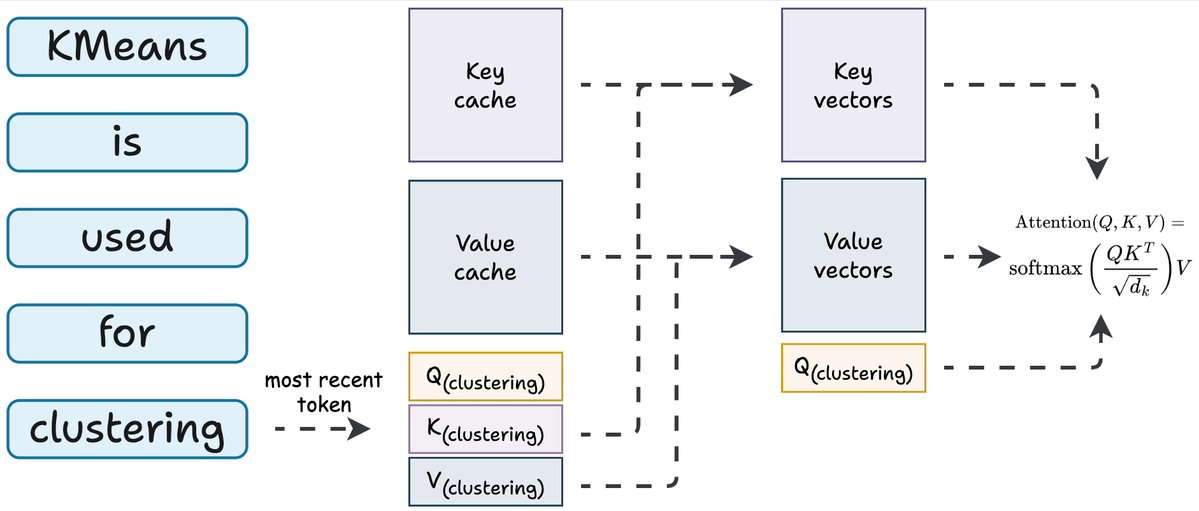
这就是 KV 缓存。每一步每个层只需要一个新的 K 和新的 V,其余全从内存读取。
注意力计算本身仍然随序列长度增长(你要关注所有的 K 和 V)。但生成 K 和 V 的昂贵投影操作,对每个 Token 只做一次,而不是每一步都做。
第五部分:首 Token 时延
现在你应该能理解为什么第一个 Token 最慢了。
当你发送一段提示词(Prompt),模型会在一次前向传播中处理整个输入,计算并缓存所有 Token 的 K 和 V 向量。这就是预填充阶段(Prefill Phase),也是整个请求中计算量最大的部分。
一旦缓存就绪,后续每个 Token 只需要对新来的那一个 Token 做一次前向传播。
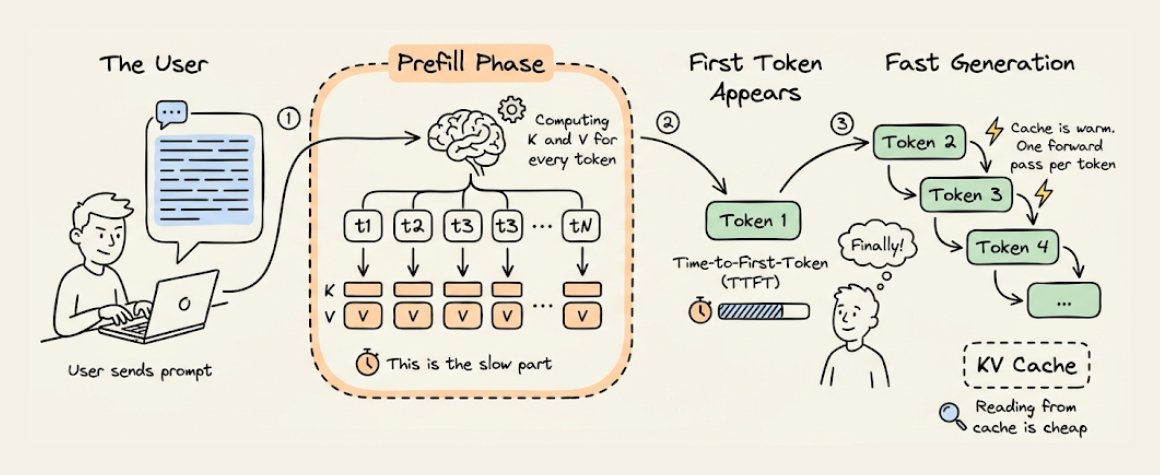
这段初始延迟叫首 Token 时延(TTFT, Time-to-First-Token)。提示词越长,预填充越久,等待越长。优化 TTFT(分块预填充、推测解码、提示缓存)本身是一个很深的话题,但底层逻辑始终不变:构建缓存很贵,从缓存读取很便宜。
第六部分:代价
KV 缓存是用计算换显存。每一层都要为每个 Token 存储 K 和 V 向量。以 Qwen 2.5 72B 为例(80 层、32K 上下文、隐藏维度 8192),单次请求的 KV 缓存就可能吃掉几个 GB 的 GPU 显存。几百个并发请求时,KV 缓存的占用常常超过模型权重本身。
这就是为什么会有分组查询注意力(GQA, Grouped-Query Attention)和多查询注意力(MQA, Multi-Query Attention):在多个查询头之间共享键/值头,大幅削减显存,质量损失却微乎其微。
这也解释了为什么翻倍上下文长度那么难。窗口翻倍,每个请求的 KV 缓存翻倍,能并发的用户就少一半。
还有另一个思路叫分页注意力(Paged Attention),就是解决这个问题的,我最近写过:
> 引用推文:Avi Chawla (@_avichawla) > https://t.co/zu8HupqrL5 > https://x.com/_avichawla/status/2031624056072712547
一句话总结
KV 缓存消除了自回归生成中的冗余计算。之前的 Token 永远产生相同的 K 和 V 向量,所以算一次存起来就行。每个新 Token 只需要它自己的 Q、K 和 V,然后用 Q 走一遍完整的缓存注意力计算。
实践中大约 5 倍加速。代价是 GPU 显存,在规模化部署中这成为核心瓶颈。所有大语言模型推理框架(vLLM、TGI、TensorRT-LLM)都构建在这个思路之上。
以上就是全部内容!
如果你喜欢这篇教程:
关注我 → @_avichawla
我每天分享数据科学、机器学习、大语言模型和 RAG 相关的教程与洞察。